


What Microsoft Fabric means for your semantic models: Scenario 2

ONE TEAM’S SEMANTIC MODEL
…an example of a scenario where a departmental analytics team goes from Power BI to Fabric
This article is part of a series: What Microsoft Fabric means for your semantic models.
Scenario 2: Decentralized analytics team (this article).
In Fabric—like Power BI—you make different choices to build and use your semantic model in different ways. Various factors will motivate your decision to use one feature or approach over another.
In this article, I highlight one example of a scenario where a team goes from using Power BI to Fabric, and have made specific choices to support their needs and their way-of-working. Specifically, this is a decentralized team of analysts who support many sales teams across their region. They don’t come from a technical background (they’re business subject matter experts who’ve grown to adopt Power BI), but have become quite proficient with Power BI over time. Their main pains are the typical ones: they have issues with the data refresh of their import models, and the performance of their DAX. Additionally, they publish straight to a workspace that serves reports in a Power BI app, so they occasionally disrupt business reports with their changes.
They hope that moving to Fabric will help them have more performant models; however, they’ll learn that there’s no magic bullet for optimizing your model and DAX.

 The purpose of this article is twofold:
The purpose of this article is twofold:
1. To demonstrate an example of how a team's workflow changes from Power BI only to Fabric.
2. To demonstrate Git integration in Fabric for semantic models and Power BI reports.
This article is intended to be informative; I'm not trying to sell you Fabric, nor endorsing a tool, feature, or approach.
VIDEO ARTICLE
The video version of this article series is available in several videos which you can find here.
SCENARIO 2: BEFORE FABRIC

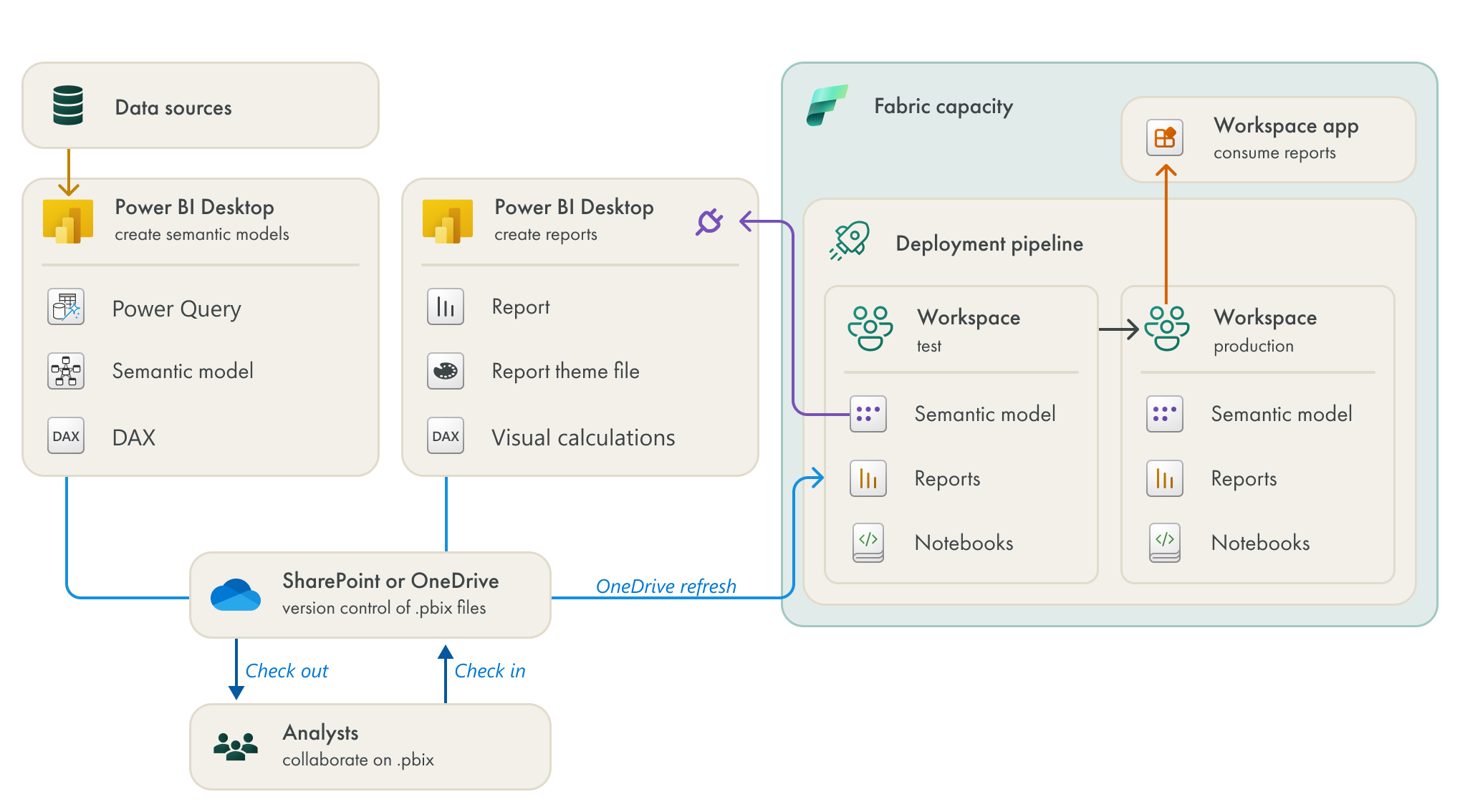
This team are a decentralized group of analysts who deliver reports and models for sales teams across their region. They are more experienced with Power BI than the first team, and have a pretty structured workflow. For instance, they are using OneDrive for version control. This team has defined a clear, structured process to check in and check out files, and use OneDrive Refresh to sync .pbix files to the workspace. However, they struggle with the performance of their model refresh and their DAX. They also regularly have issues with their updates disrupting business reports.
SCENARIO DIAGRAM: BEFORE FABRIC

This diagram reflects the quite common approach that this team takes to deliver value with Power BI. It highlights the areas where they perceive pains, but also illustrating that they publish directly to a single workspace where they deliver content to users.
The team struggles with performant Power Query; their data refreshes are quite long (~1h) although their data is quite small (approx. 16-20M rows in 3 fact tables, with standard cardinality)
The team also struggle with performant DAX. They aren’t experts in DAX but have to deal with quite complicated business logic. They need to account for a lot of exceptions, and serve reports with dynamic currency conversion for 3 different exchange rate types. This is something that they struggle with both in their model DAX and visual calculations, which they only just started using.
The team use a single workspace. While they have a structured and effective process for version control and deployment of .pbix files that works for them, it regularly disrupts business reports. They don’t have any lifecycle management aside from the version control they put in place just to more easily collaborate.
After the BI team implemented Fabric, this team hoped it would result in more performant models. However, after some testing, they understood that not a lot changed for them - at least in the short-term.
SCENARIO 2: AFTER FABRIC
Unlike team 1, this team’s workflow doesn’t actually change that much in Fabric.
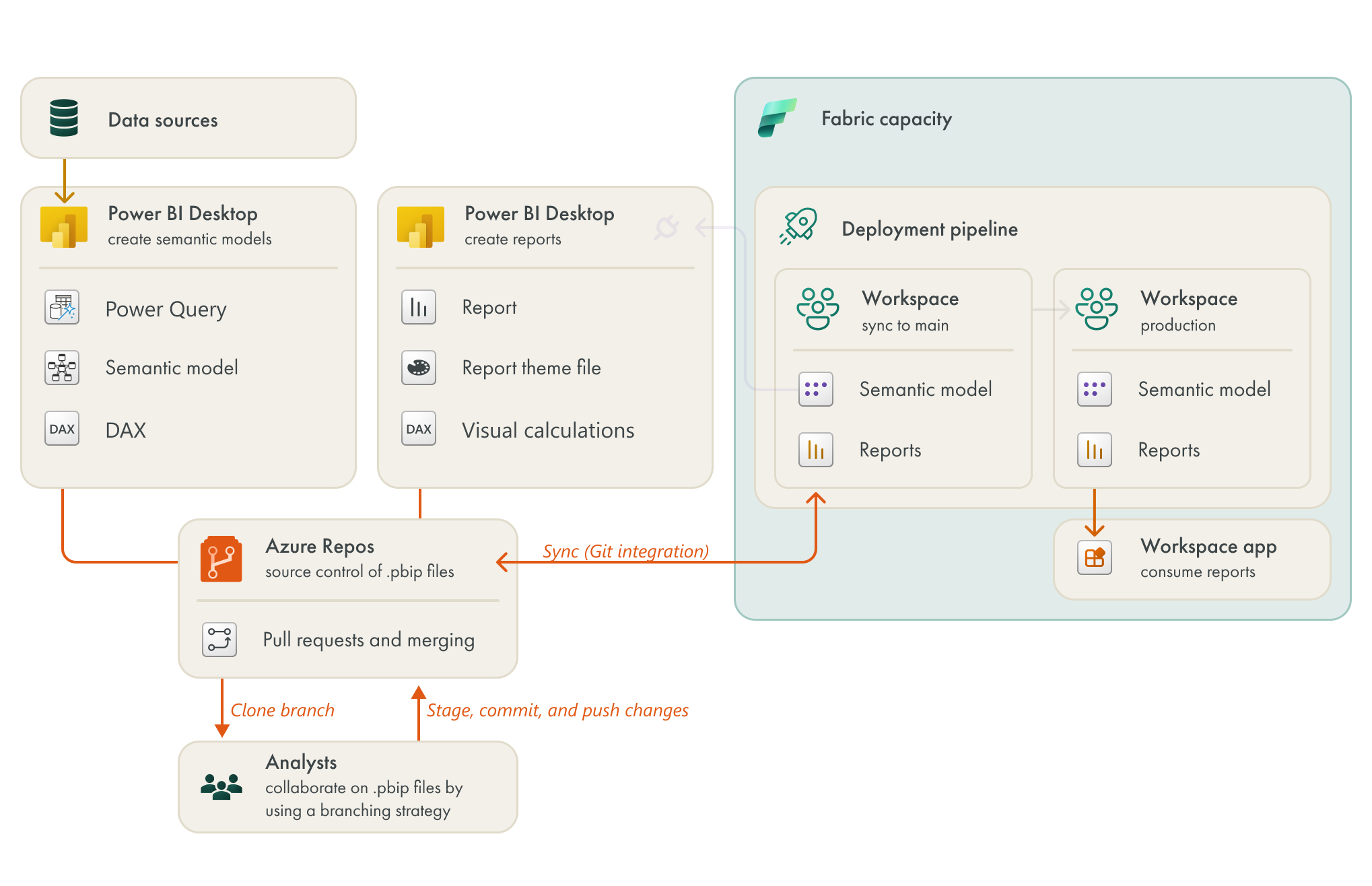
SCENARIO DIAGRAM: AFTER FABRIC
There are only a few changes in how this team is developing semantic models, but they are significant changes.
The team decided to separate production from test workspaces. They decided that they only needed two separate stages, as they perform most of their development locally by using Power BI Desktop. They then perform user testing and validation in the test workspace before they deploy to production.
They deploy content from test to production by using deployment pipelines. This way of working introduces some new steps in their workflow (like deployment and post-deployment steps), but it helps their content become more stable for business users. Deployment pipelines aren’t new to Fabric, and were already in Power BI Premium, so the central BI team has no issues training this team to work this way.
This team are also using notebooks. It doesn’t take this team long to realize that they can easily automate certain model management tasks by using notebooks and semantic link. There’s already a lot of code snippets publicly available that they are using for numerous tasks. Even though this team doesn’t know much Python or PySpark, they are using generative AI to do useful things. For instance, they’ve set up some simple automated testing to ensure the quality of their models, in terms of the data, logic, and performance. I’ll give a full demonstration of this in the video article.
Like Team1, this team also needs to learn about notebook scheduling and CU usage.
The team also gets benefits of all the other various premium features, like XMLA endpoints, larger model sizes, and so forth.
Interestingly, this team continues to use OneDrive for verison control, and develop import models intead of Direct Lake. Why is that?
WHY AREN’T THEY USING GIT INTEGRATION?
When the team started using Deployment Pipelines, they realized that they had the ability to perform a Change Review to compare changes between Test and Production workspaces. They decided to perform more regular testing and deployment, viewing the changes this way and using the deployment notes to describe the content of those changes. Together with their existing system of OneDrive for version control, they felt like this met their needs.


The team discussed with the central BI team whether they’d use Git integration, and decided against it. The reasons are as follows:
They don’t have the time and resources to learn: The team understood that they’d need to learn Git, which is very complicated for new learners like them. At the moment, the team doesn’t have time to learn that much, and they didn’t feel the urgency or see the value in spending that time right now, particularly since there were multiple ongoing sales intiaitives they needed to support.
It involved new tools: The team understood that at minimum they’d need to learn to use Azure DevOps (Azure Repos) and Visual Studio Code (or another SCM GUI). While neither of these tools seemed particularly complicated, the team agreed that it was not feasible for them to dedicate the appropriate time to learn these tools, now. Their manager also wanted more clarity about the DevOps licensing, which also took time.
It felt overcomplicated: In general, the Git integration process seemed complicated to this decentralized team. However, in reality, it wasn’t that far from their current process. After some discussion, they decided to prepare to start using Git integration in the future, once they could get the time to learn the appropriate tools and processes.
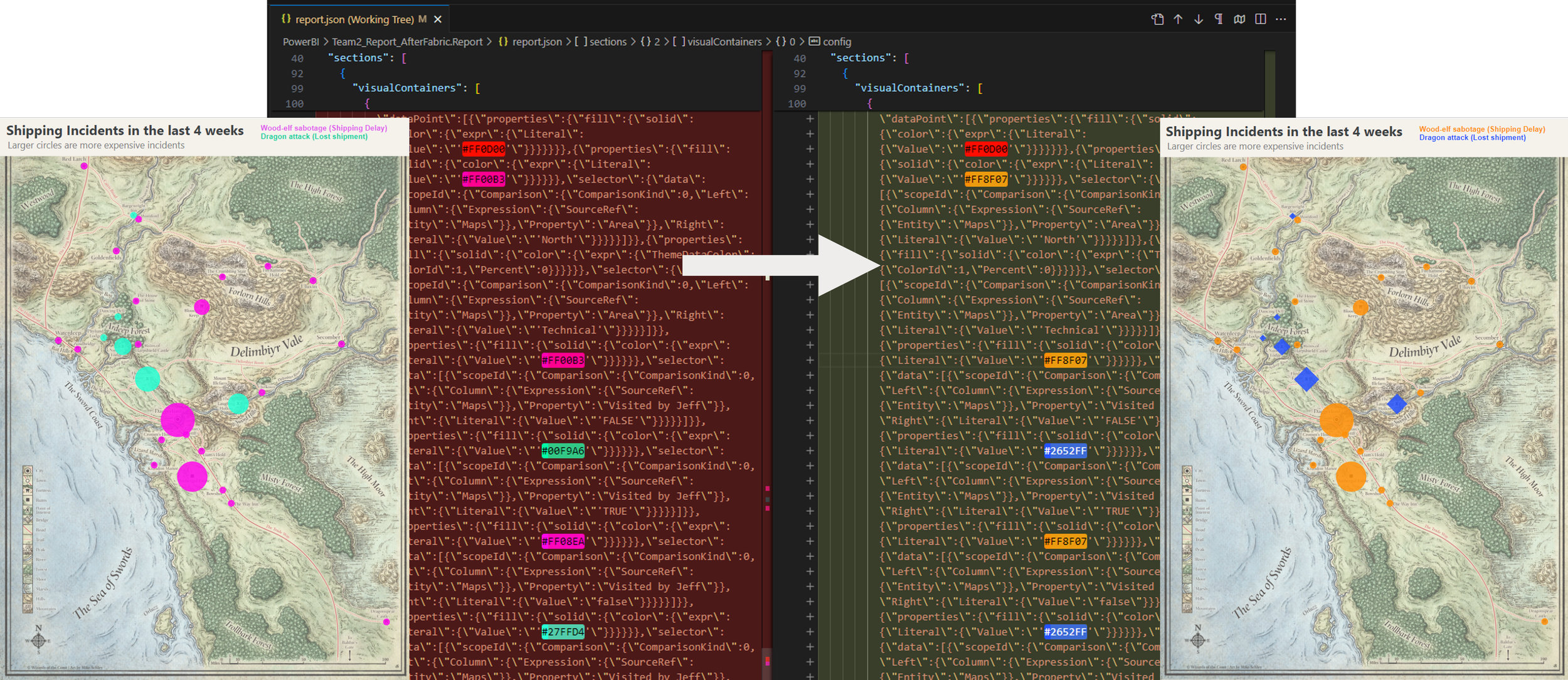
The team is currently testing a proof-of-concept for source control with their models and reports, to get familiar with the tools and concepts they must know to be successful. More importantly, it helps them identify whether it’d bring added value and improve their effectiveness. For example, they like that in VS code that they can use extensions to identify functionally important metadata that might change, like colors in reports.
WHY AREN’T THEY USING DIRECT LAKE?
The team had been hearing a lot about Direct Lake since Fabric was announced, and expected that it would solve their performance problems in Power Query and DAX. They expected to move their data transformations upstream to Dataflows Gen2, land their data in OneLake, and in either a Lakehouse or Warehouse have their business-ready data that they could connect to from their Power BI semantic model. They expected that this semantic model would be more performant than their current import model.
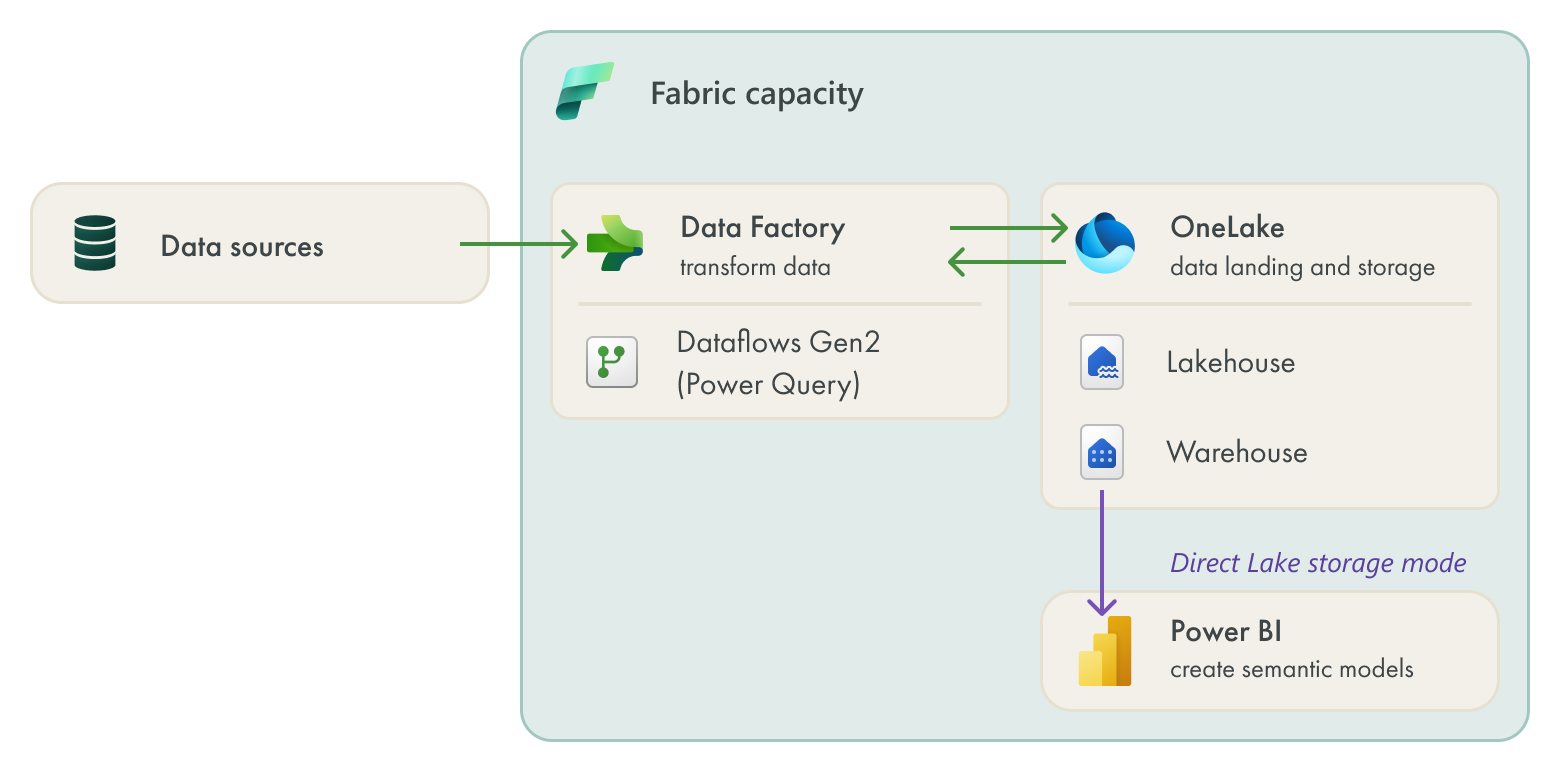
In reality, this team misunderstood Direct Lake and its benefits; Direct Lake is not going to automagically solve their performance issues. They could have perfectly well adopted the approach illustrated in the above diagram, although it would result in the following:
Their performance issues in Power Query would simply be pushed upstream to the dataflow: The issue lies in how they authored and are using their Power Query. They haven’t dedicated the appropriate time to learning how to optimize Power Query, and as such, there are still basic improvements they can make in their import model, like leveraging query folding.
Their performance issues in DAX wouldn’t go away: The issues with their DAX performance are from a combination of certain modeling choices and DAX choices they’ve made to support the mountains of business exceptions and complex logic they need to create. In Direct Lake, many of their DAX queries would fallback to DirectQuery and have even worse performance. Instead, they need to optimize their model and DAX, and spend time testing more optimal patterns for their specific logic and scenarios.
Even assuming this team could resolve both their Power Query and DAX performance before a Direct Lake migration, they still have the following challenges:
Added complexity: This team is comfortable with managing Power BI models and reports, but they’ve never managed dataflows, data lakehouses, or data warehouses before. This would shift their way of working from strictly modeling and reporting to managing a full architecture. While scaling might require that they do this at some point, currently, it would be adding tremendous complexity to their workflow. The team would have to skill up dramatically, or hire additional consultants to help complete and manage this migration.
Direct Lake considerations: The team would have to completely adjust their way of working to support the Direct Lake model for the following reasons:
Tooling: They’d have to manage the Direct Lake model from the workspace (as of Feb 2024) or external tools (which they don’t know how to use) because it’s not supported in Power BI Desktop.
Version control: Direct Lake models created in the Fabric Portal aren’t supported by Git integration, and they couldn’t feasibly save a version of the model in OneDrive.
Collaboration: They’d risk overwriting eachother’s changes in the Fabric portal, because they are working using web authoring, where changes are instantly saved. They’d not be able to feasibly collaborate effectively using this method.
Direct Lake considerations: There are completely new concepts to know when it comes to Direct Lake, so they’d have to take these into account. While this isn’t a problem, it’s a tax they’d have to pay to use Direct Lake effectively:
Fallback behavior
Refresh and framing of new data
Initial query times (when paged out of memory)
Optimization (i.e. of underlying delta tables)
Case-sensitive collation
TO CONCLUDE

In this second scenario, a decentralized BI team moves to Fabric. They get value from the Premium features, but don’t immediately use all the new Fabric items and features. They choose the tools and features that give them value now, and keep parts of their current workflow that make sense. Specifically, they don’t opt for a Direct Lake model or Git integration both to avoid added complexity and because they realize that their current pains are mainly a result of their own processes and poorly-optimized model.
However, this team educates themselves about the available options, and plans proof-of-concepts or trainings to understand the value these new features and approaches might bring. For example, the team are testing Git integration, and have already explored Direct Lake models and made the decision that for their specific scenario Direct Lake isn’t yet the best option.

